人工智能基础软件开发:从零理解神经网络
引言:为什么神经网络是人工智能的核心?
人工智能(AI)正以前所未有的速度改变着我们的生活,从智能手机的人脸识别到自动驾驶汽车,其背后大多离不开一种名为“神经网络”的技术。对初学者而言,神经网络听起来可能高深莫测,但它其实是一个模仿人类大脑工作方式的数学模型。本篇文章将用最通俗易懂的语言,带你迈出理解神经网络的第一步,并了解如何通过基础软件开发将其实现。
第一部分:神经网络是什么?一个生动的比喻
想象一下,你第一次学习辨认一只猫。
- 你看到一张图片(输入)。
- 你的大脑会分析特征:它有尖耳朵、胡须、椭圆形的眼睛和毛茸茸的尾巴(特征提取)。
- 你将这个组合与你记忆中“猫”的概念进行比对(模式匹配)。
- 最后得出结论:“这是一只猫!”(输出)。
神经网络的工作流程与此惊人相似:
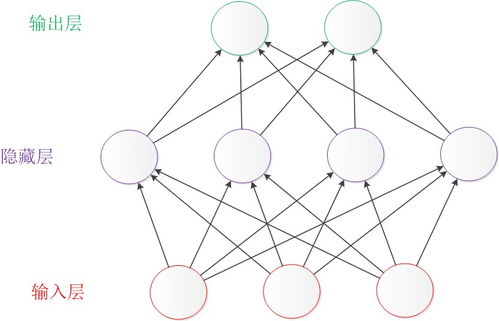
- 输入层: 接收原始数据(如图像的每个像素点)。
- 隐藏层: 由众多“神经元”(或称节点)组成,每个神经元负责检测某种简单特征(如边缘、颜色块)。层数越多,能识别的特征就越复杂。
- 输出层: 给出最终判断或结果(如“猫:95%概率”)。
数据在这些层中向前流动,就像信息在大脑的神经元网络中传递一样,因此得名“神经网络”。
第二部分:核心基石——“神经元”如何工作?
一个最简单的人工神经元(或称感知器)做三件事:
- 接收输入:每个输入(比如像素的亮度值)都乘以一个“权重”。权重代表了该输入的重要程度。耳朵特征的权重可能比背景特征的权重大得多。
- 加权求和:将所有加权后的输入加起来,再加上一个“偏置”(一个调整项,帮助模型更好地拟合数据)。
- 激活判断:将求和结果送入一个“激活函数”。你可以把它想象成一个开关或过滤器,它决定这个神经元是否被“激活”(即输出一个较强的信号)。常用的激活函数如Sigmoid或ReLU,能将结果映射到一个固定范围内。
简单公式表示: 输出 = 激活函数( (输入1 × 权重1) + (输入2 × 权重2) + ... + 偏置 )
成千上万个这样的简单神经元连接在一起,就能完成极其复杂的识别任务。
第三部分:基础软件开发入门——用Python构建你的第一个神经网络
理解了概念,我们来看看如何用代码实现它。Python因其丰富的AI库(如TensorFlow, PyTorch)而成为首选语言。
环境准备:
- 安装Python(推荐3.8以上版本)。
- 安装核心库:在命令行中运行 pip install numpy matplotlib tensorflow。
一个极简的代码框架:
`python
import numpy as np
import tensorflow as tf
from tensorflow import keras
1. 数据准备:用经典的MNIST手写数字数据集为例
mnist = keras.datasets.mnist
(trainimages, trainlabels), (testimages, testlabels) = mnist.loaddata()
trainimages, testimages = trainimages / 255.0, test_images / 255.0 # 归一化,将像素值压缩到0-1之间
2. 构建神经网络模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)), # 输入层:将28x28的图片展平为784个像素点
keras.layers.Dense(128, activation='relu'), # 隐藏层:128个神经元,使用ReLU激活函数
keras.layers.Dense(10, activation='softmax') # 输出层:10个神经元(对应0-9十个数字),使用Softmax函数输出概率
])
3. 编译模型:配置学习过程
model.compile(optimizer='adam', # 优化器:决定如何根据误差调整权重
loss='sparsecategoricalcrossentropy', # 损失函数:衡量模型预测值与真实值的差距
metrics=['accuracy']) # 评估指标:这里关注准确率
4. 训练模型:让模型从数据中学习
model.fit(trainimages, trainlabels, epochs=5) # 训练5轮
5. 评估模型
testloss, testacc = model.evaluate(testimages, testlabels, verbose=2)
print(f'\n测试准确率:{test_acc}')
6. 进行预测
predictions = model.predict(test_images)
print(f'第一张测试图片的预测结果(概率分布):{predictions[0]}')
print(f'预测数字是:{np.argmax(predictions[0])}')`
代码解读:
- 我们构建了一个最简单的三层(输入层、一个隐藏层、输出层)全连接网络。
- model.fit 是核心训练过程,模型会自动调整所有神经元的权重和偏置,以最小化预测误差。这个过程称为“反向传播”和“梯度下降”,我们将在下篇文章详细讲解。
- 运行这段代码,你将得到一个能够识别手写数字的AI程序!虽然简单,但它包含了神经网络软件开发的所有核心步骤。
第四部分:关键概念梳理
- 前向传播: 数据从输入层流向输出层,得到预测结果的过程(如上文代码中的
predict步骤)。 - 损失函数: 衡量模型“错得有多离谱”的尺子。训练的目标就是最小化这个值。
- 优化器: 损失函数的“导航仪”,它根据损失值计算如何调整网络中的权重(最常用的是Adam)。
- epoch(轮次): 将全部训练数据完整学习一遍称为一个epoch。
与下篇预告
至此,你已经对神经网络有了最直观的理解,并且成功运行了第一个神经网络程序。你看到了它如何像大脑一样分层处理信息,也看到了用高级框架(如TensorFlow)可以如何简洁地实现它。
我们只是让模型“运行”了起来,它内部最精妙的学习机制——“模型是如何通过数据自动调整权重(即学习)的?”——尚未揭晓。这正是神经网络被称为“学习”的关键。
在下篇文章中,我们将深入神经网络的“学习引擎”,用最清晰的图解和类比,揭秘 “反向传播” 和 “梯度下降” 的奥秘,并探讨更复杂的网络结构(如卷积神经网络CNN)。你将彻底明白,人工智能是如何从数据中自我成长的。
让我们保持好奇,一起深入AI的核心。